
구글과 네이버의 지원을 얻고, 음성인식기술, 문자인식기술(OCR)을 보다 쉽고 훌륭한 품질로 사용할 수 있습니다.
현재 OCR기술은 북스캔 뿐만 아니라, 다양한 용도로 사용되고 있으며, 정확도 역시 높습니다.
문자를 인식하는 정확도는 높지만, 복잡한 표가 들어있는 문서에서 표(테이블) 속에 들어 있는 데이터를 사용할 수 있는 OCR 기술은 아직도 많이 부족합니다.
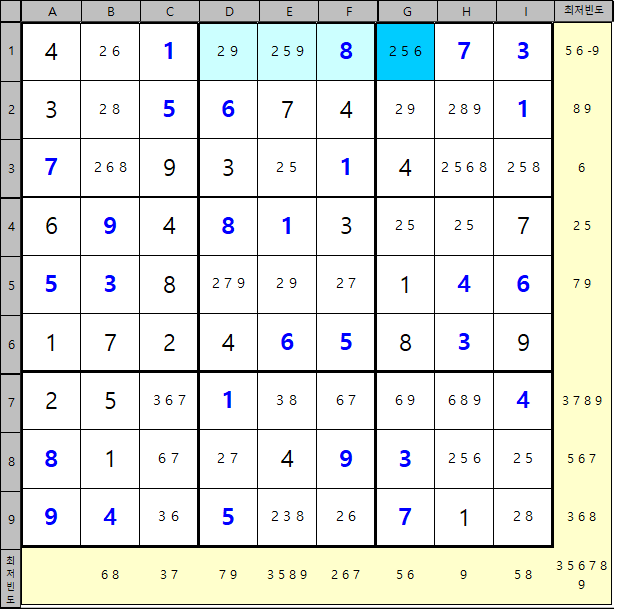
예를 들면 위 이미지를 네이버 크로바 OCR로 인식시키면 다음과 같은 테이터로 반환합니다.
| A B C D E F G H | 최저빈도 1 4 26 1 29 259 8 256 7 3 56-9 2 3 28 5 6 7 4 29 289 1 89 3 7 268 9 3 25 1 4 2568 258 6 4 6 9 4 8 1 3 25 25 7 25 5 5 3 8 279 29 27 1 4 6 79 6 1 7 2 4 6 5 8 3 9 7 2 5 367 1 38 67 69 689 4 3789 8 8 1 67 27 4 9 3 256 25 567 9 9 4 36 5 238 26 7 1 28 368 최저빈도 35678 68 37 79 3589 267 56 9 58 9 |
OCR로 문서 인식 결과는 양호합니다. 가로 한글도 잘 인식하고, 세로로 있는 한글도 정확히 인식했습니다.
단지 영어 대문자 "I"와 "|"(파이프 문자)를 구분하지 못 했습니다.
테이블을 데이터로 사용하고 싶은 마음에 간단한 OCR 프로그램을 만들어서, 사용한 결과 생각보다 꽤 쓸만해서 포스트 합니다.

(제가 만든 OCR 프로그램으로 엑셀에 데이터로 붙여 넣은 모습)
100% 데이터화 되지는 못했지만, 조금만 수정하면 쓸수 있는 데이터가 생성되었습니다.
회사에서 업무를 하다보면 다량의 데이터 작업을 해야 하는 경우가 있습니다. 이때, PDF파일 등에서 데이터를 추출하여 사용하면 편리합니다.
이미지 또는 PDF파일 일반 문자를 OCR로 추출해서 데이터하는 작업도 함께 진행 중 입니다.
이미지 추출해서 데이터로 전환하고, 엑셀 파일로 만드는 프로그램은 유료 프로그램입니다.
관심있는 분들은 댓글 또는 이메일로 연락 주세요.





















ABBYY사의 레티아로 표를 인식한 결과
상당히 훌륭한 인식결과를 보여줍니다.